k
j
![]()
mrCAD: Multimodal Communication to Refine Computer-aided Designs
Abstract
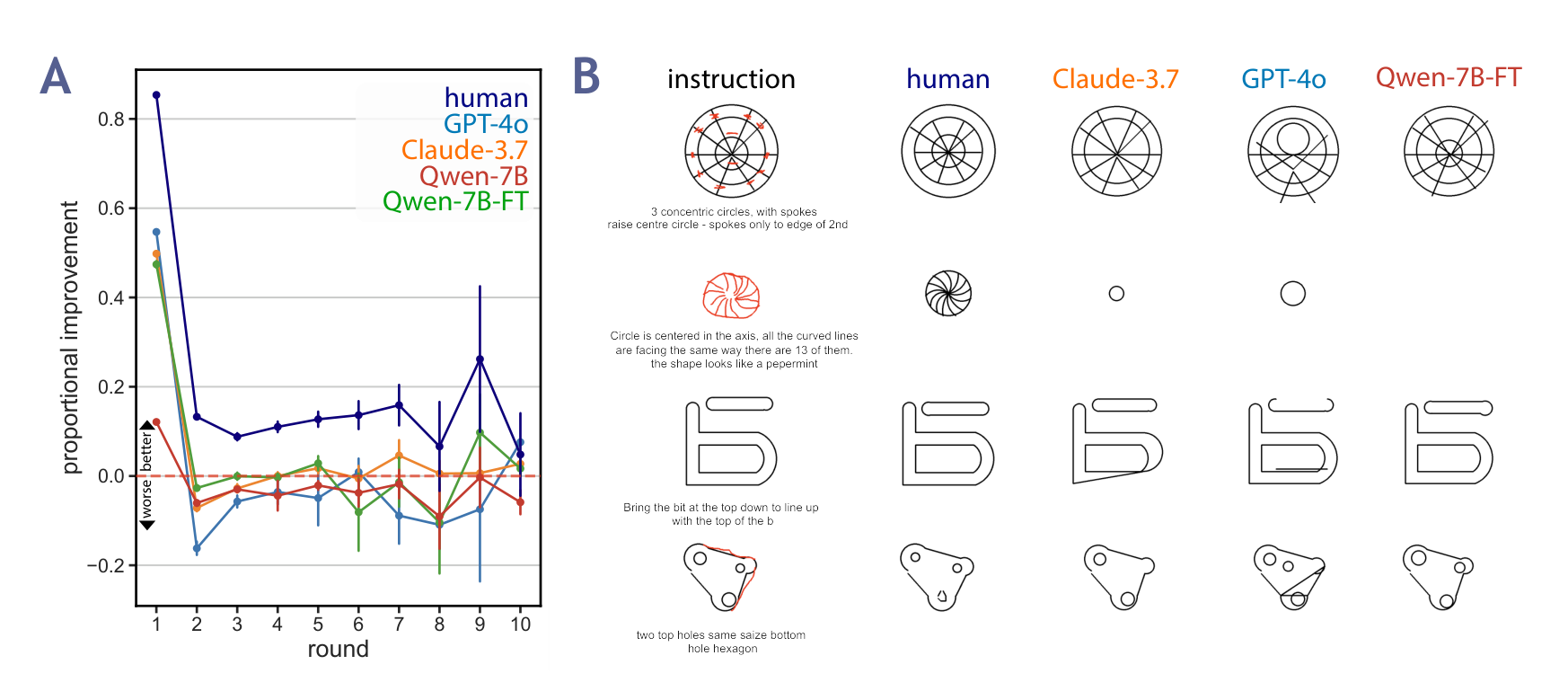
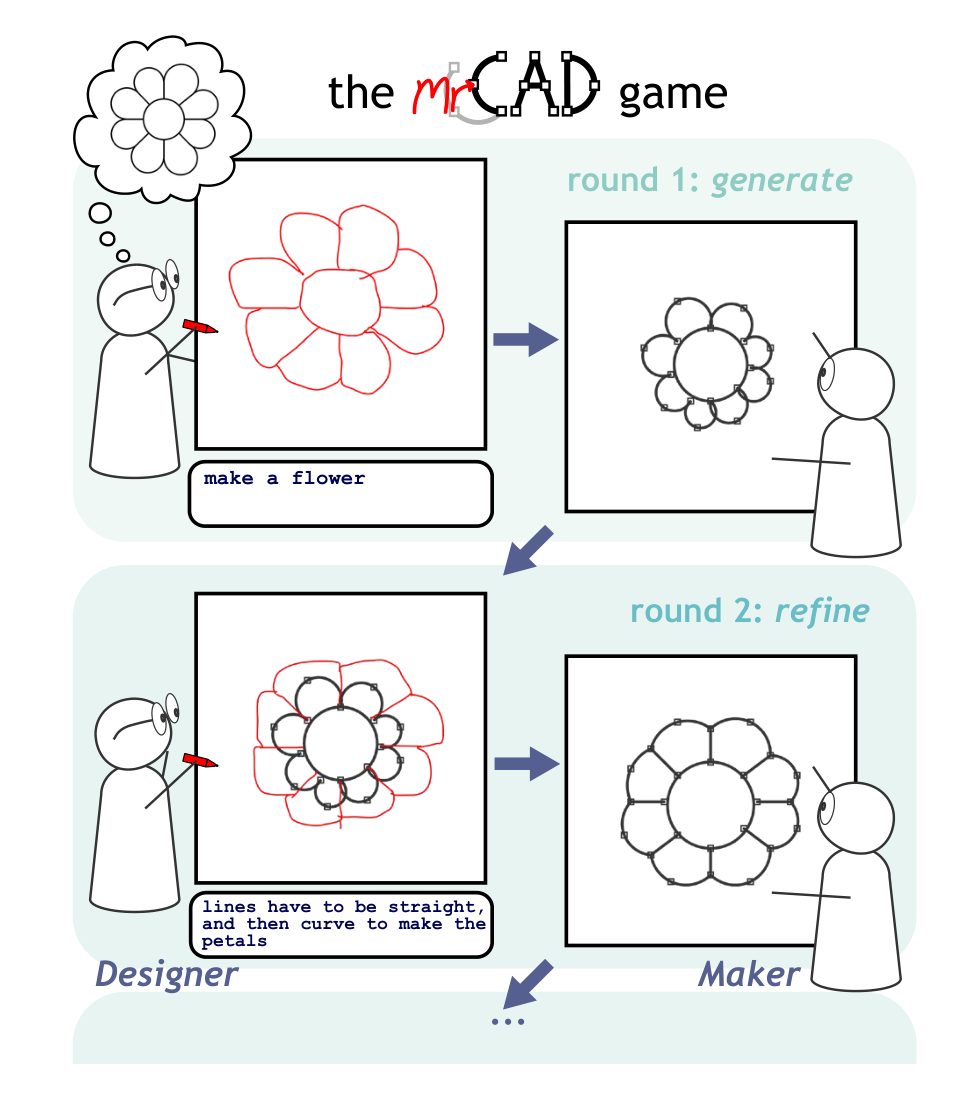
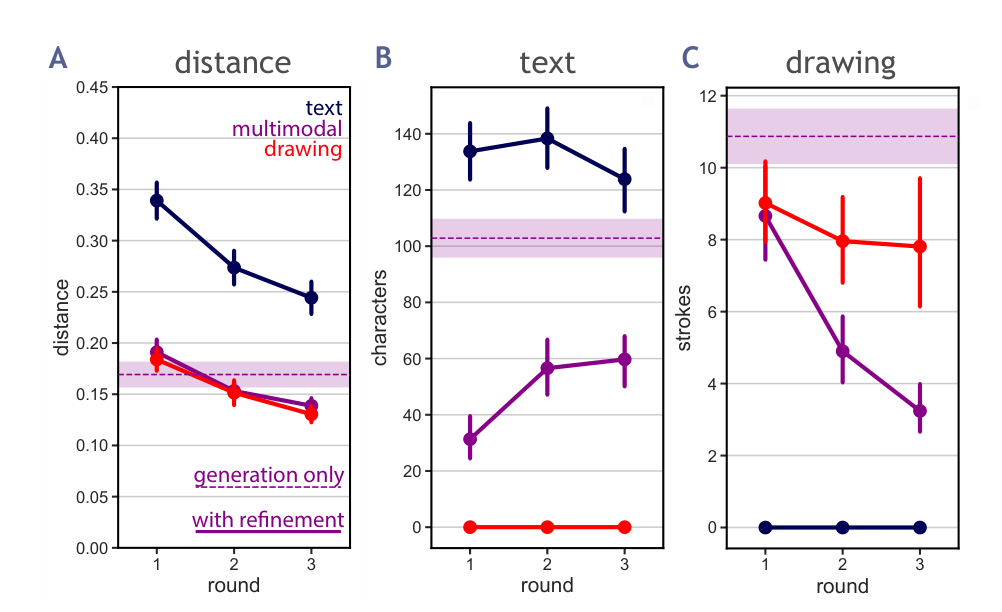
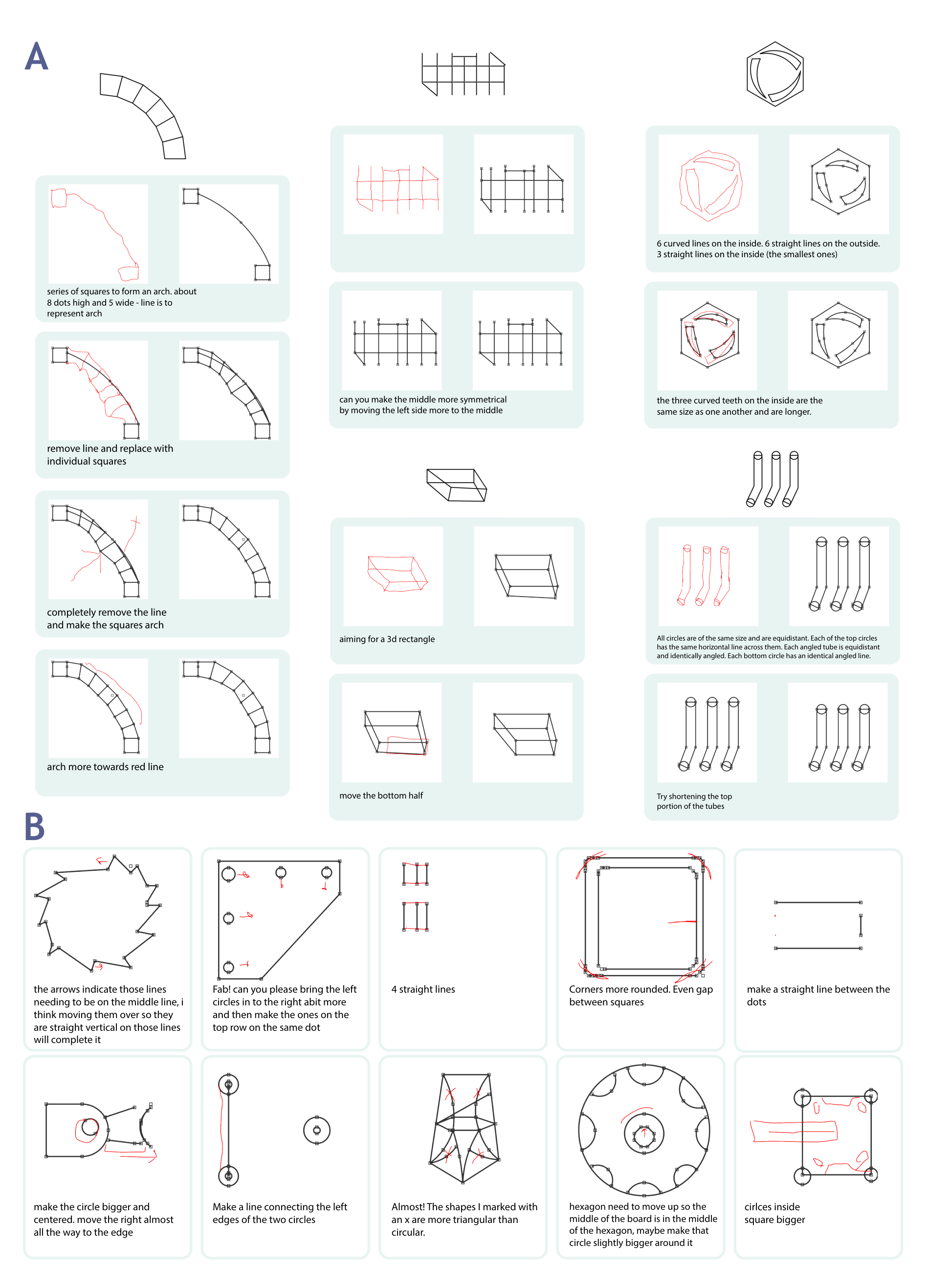
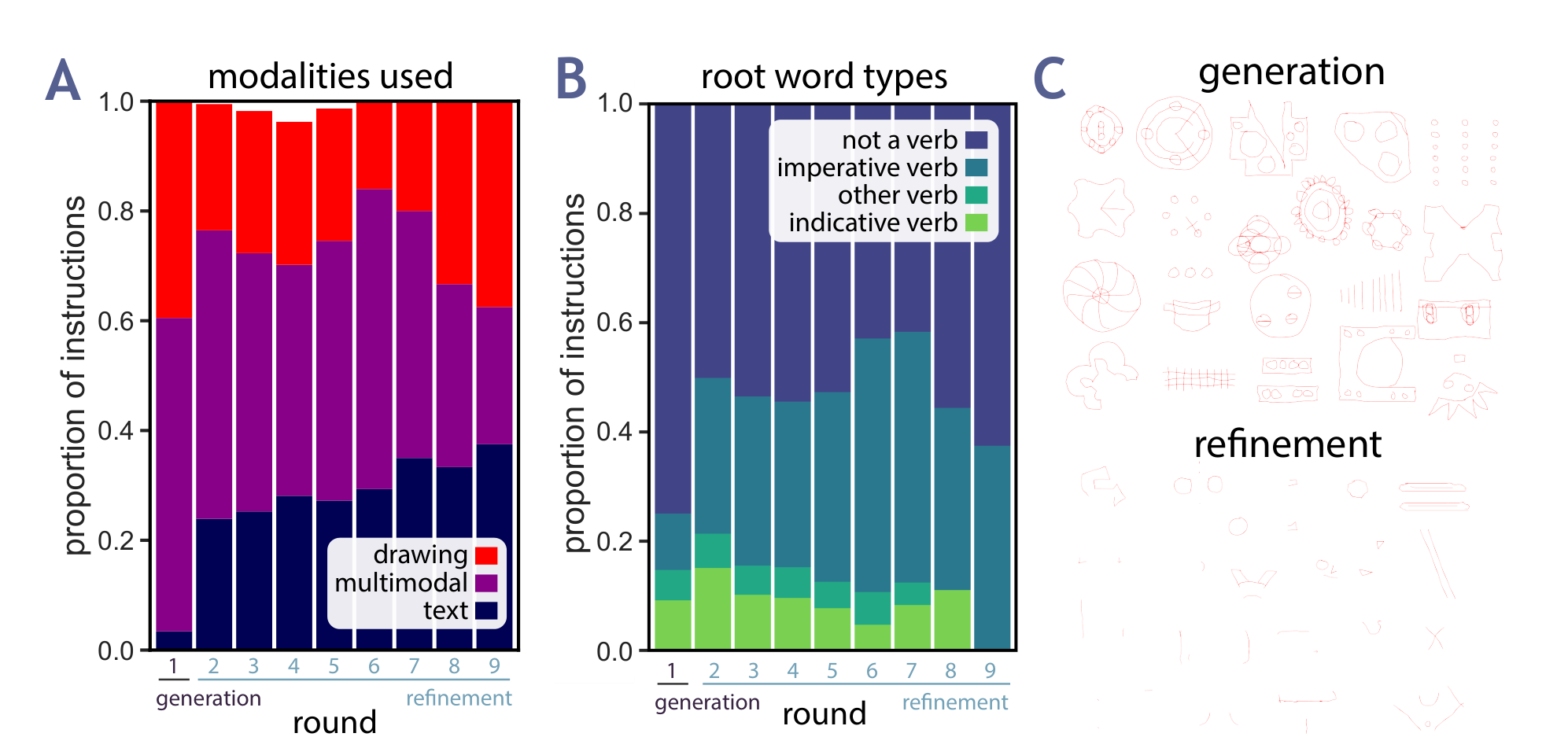
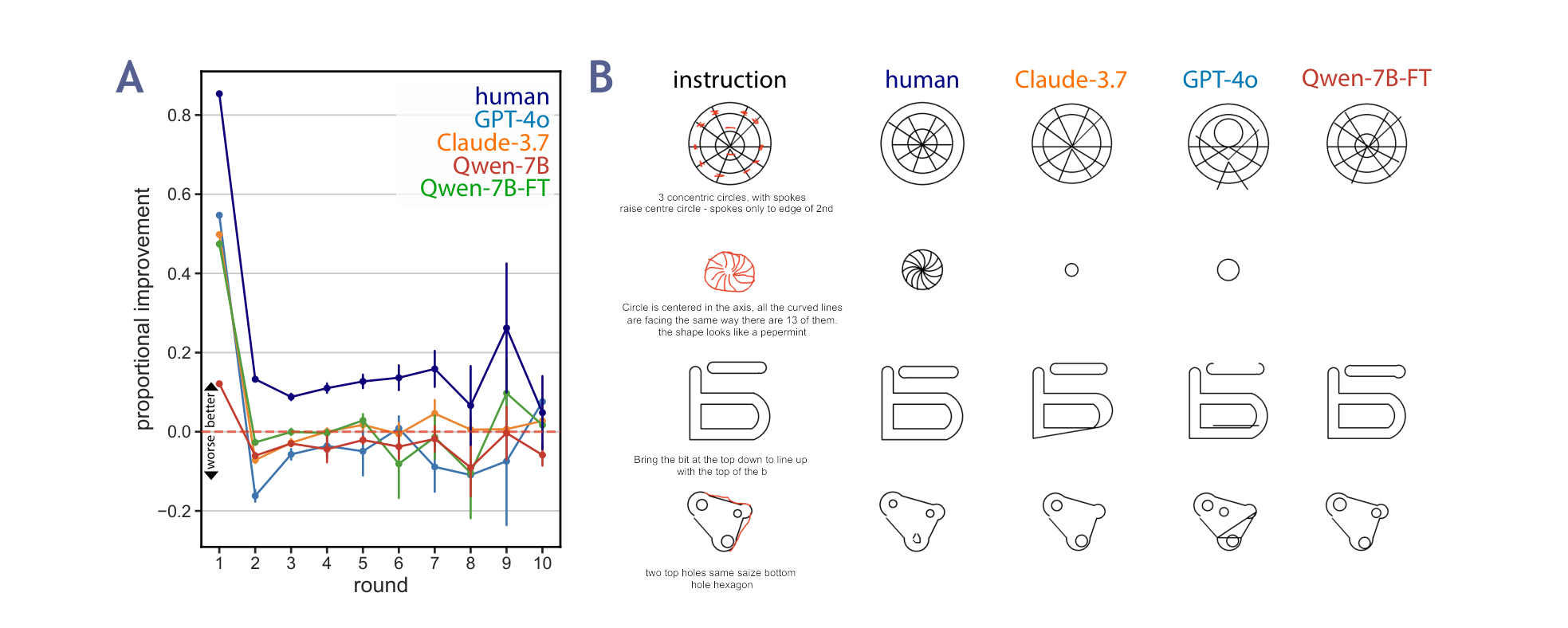
In collaborative creation tasks, people steer artifacts towards specific goals by \_refining\_ them with \_multimodal\_ communication over multiple rounds of interaction. In contrast, generative AI excels at creating artifacts in a single turn but can struggle to make precise refinements that match our design intent. To close this gap, we present mrCAD, a dataset of multi-turn interactions in which pairs of humans iteratively created and refined computer-aided designs (CADs). In each game, a \_Designer sent instructions to a \_Maker\_
Figures
BibTeX
@inproceedings{mccarthy-etal-2025-mrcad,
title = "mr{CAD}: Multimodal Communication to Refine Computer-aided Designs",
author = "McCarthy, William P and
Vaduguru, Saujas and
Willis, Karl D.d. and
Matejka, Justin and
Fan, Judith E and
Fried, Daniel and
Pu, Yewen",
editor = "Christodoulopoulos, Christos and
Chakraborty, Tanmoy and
Rose, Carolyn and
Peng, Violet",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2025",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.findings-emnlp.1248/",
doi = "10.18653/v1/2025.findings-emnlp.1248",
pages = "22905--22921",
ISBN = "979-8-89176-335-7",
abstract = "In collaborative creation tasks, people steer artifacts towards specific goals by {\_}refining{\_} them with {\_}multimodal{\_} communication over multiple rounds of interaction. In contrast, generative AI excels at creating artifacts in a single turn but can struggle to make precise refinements that match our design intent. To close this gap, we present mrCAD, a dataset of multi-turn interactions in which pairs of humans iteratively created and refined computer-aided designs (CADs). In each game, a {\_}Designer sent instructions to a {\_}Maker{\_}, explaining how to create and subsequently refine a CAD to match a target design that only the {\_}Designer{\_} could see. mrCAD consists of 6,082 communication games, 15,163 instruction-execution rounds, played between 1,092 pairs of human players. Crucially, {\_}Designers{\_} had access to two communication modalities {--} text and drawing. Analysis finds that players relied more on text in refinement than in initial generation instructions, and used different linguistic elements for refinement than for generation. We also find that state-of-the-art VLMs are better at following generation instructions than refinement instructions. These results lay the foundation for modeling multi-turn, multimodal communication not captured in prior datasets."
}